
采集其实可以直接用后端的curl使用,不过有些网页是需要ajax加载后才显示内容的不好采集,有些内容还是加密的,使用以下方法就可以解决这些问题
现在使用python+selenium+chromedriver插件这个方法就可以采集js展示后的内容
首先下载 chromedriver插件 https://chromedriver.storage.googleapis.com/index.html
这是版本对照链接: http://chromedriver.storage.googleapis.com/2.40/notes.txt
我的谷歌浏览器版本是
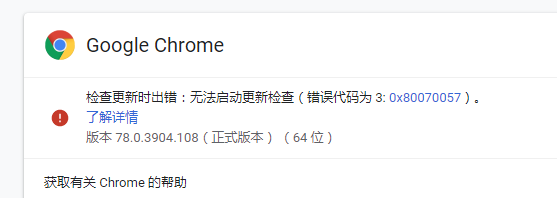
所以我下载了这个
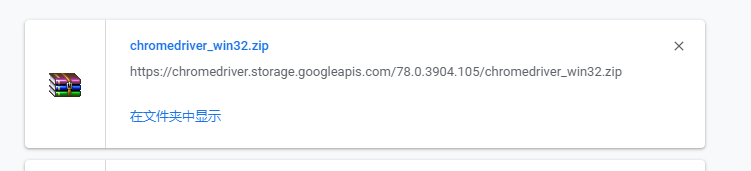
把这个文件解压放到谷歌浏览器根目录后添加环境变量如:
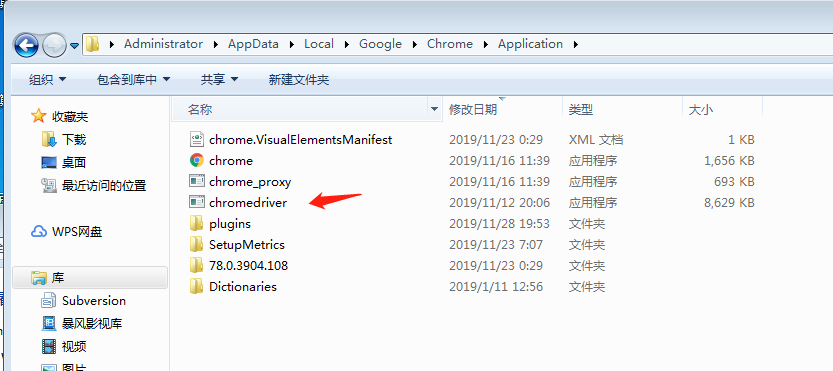
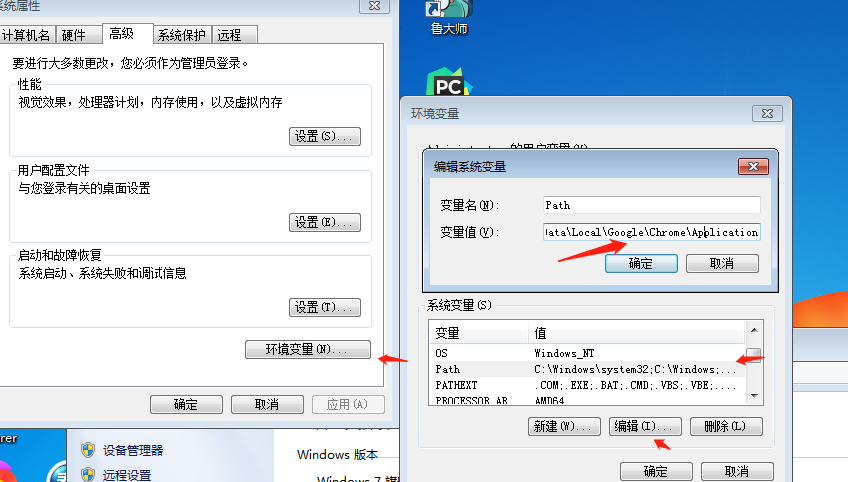
这里注意重启电脑,我没重启测试不行
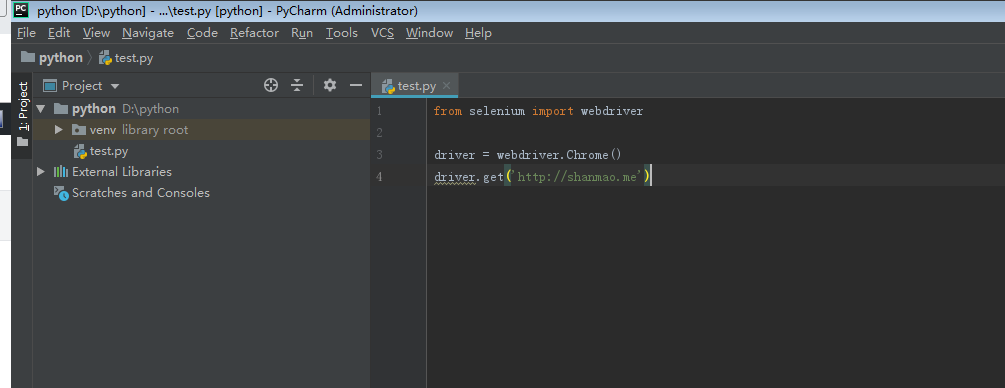
输入测试代码:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://shanmao.me')
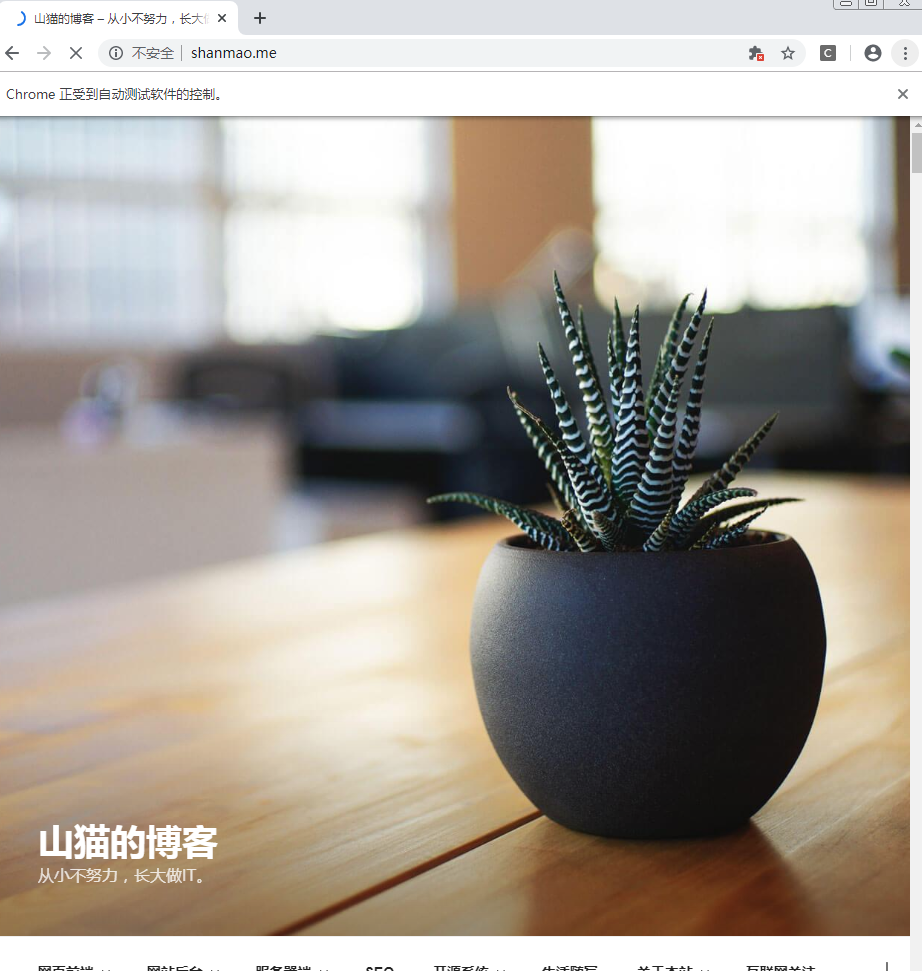
测试结果如下:
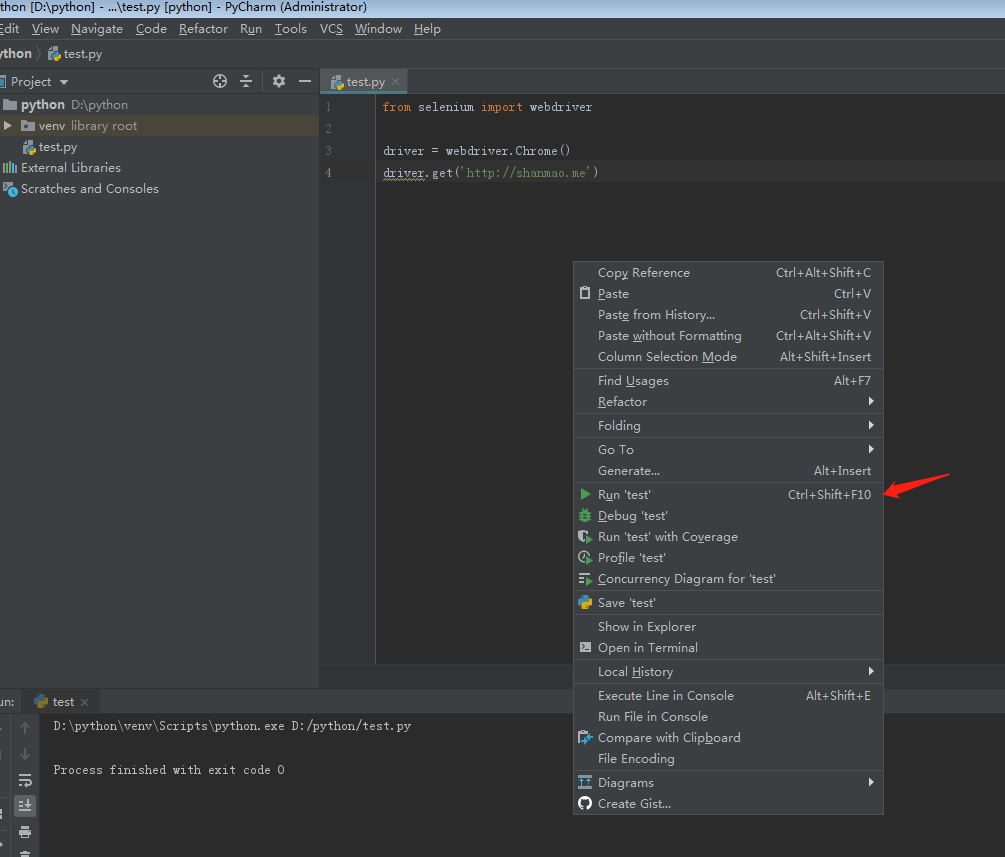
右击运行后:
这样基本流程就通了后面就是采集数据