
安装:pip install beautifulsoup4
模拟登录并获取html代码内容
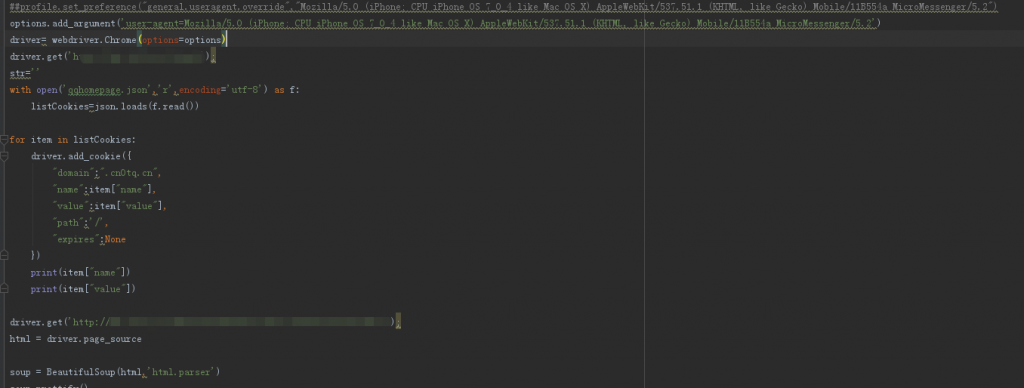

其中cookie添加部分比较麻烦折腾了几十分钟
写入cookie:
cookie = driver.get_cookies()
jsonCookies = json.dumps(cookie)
with open('qqhomepage.json', 'w') as f:
f.write(jsonCookies)
str=''
with open('qqhomepage.json','r',encoding='utf-8') as f:
listCookies=json.loads(f.read())
for item in listCookies:
driver.add_cookie({
"domain":".xxx.cn",
"name":item["name"],
"value":item["value"],
"path":'/',
"expires":None
})
print(item["name"])
print(item["value"])
相关文档 https://www.crummy.com/software/BeautifulSoup/bs4/doc/
解析区间内的所有图片:
html = driver.page_source
soup = BeautifulSoup(html,'html.parser')
soup.prettify()
htmlrr = soup.select('#ChapterContent10576198 img');
print(htmlrr)